
W bibliotekach ITIL definicja problemu reprezentuje istniejącą niezidentyfikowaną przyczynę powstawania incydentów. Wiele incydentów o podobnej specyfice może wskazywać na problem. Sporo osób myli te pojęcia. Celem procesu zarządzania problemami jest identyfikacja, analiza i eliminacja problemów tak aby nie implikowały powstawania wielu incydentów.
Zarządzanie problemami może być reaktywne, kiedy są one identyfikowane już po powstaniu oraz proaktywne, kiedy przeciwdziała się przed ich zaistnieniem.
W tym procesie nie zachodzą etapy przekazywania informacji, ponieważ ich obsługą zajmują się zazwyczaj technicy drugiej linii wsparcia. Presja czasowa jest tutaj mniejsza niż w przypadku incydentów, ale nie umniejsza wartości dla biznesu, ponieważ właściwa kontrola nad problemami zwiększa dostępność usług dla organizacji.
Praktyki ITIL nie definiują wprost kroków dla właściwego podejścia w procesie zarządzania problemami jednak identyfikują kilka kluczowych czynności, które powinny się w nim znaleźć jak:
- Detekcja problemu
- Rejestracja problemu
- Kategoryzacja
- Priorytezacja
- Badania i diagnoza
- „obejście” – tymczasowa naprawa przed właściwym wyeliminowaniem problemu
- Rozwiązanie i zamknięcie
[ITIL Foundation Handbook, 213]
Samo zdefiniowanie procesu to jedno, pozostaje jednak kwestia metody jaka powinna zostać użyta do faktycznej analizy problemów i znajdowania rozwiązań.
Tutaj ITIL odwołuje się do znanych metod takich jak:
- Analizy chronologiczne
- Metoda Kepner-Tregoe
- Burzy mózgów
- Izolacji błędów
- Diagram Ishikawa
i inne.
“Problemem” zarządzania problemami jest właśnie faza analizy przyczyn powstawania incydentów. ITIL niestety nie pokazuje dokładnych sposobów na wydajne i efektywne wykrywanie źródeł niestabilności w działaniu usług oraz występowaniu w nich błędów. Metodyka ta skupia się na standaryzacji podejścia oraz etapowym procesie postępowania. Krótko mówiąc odpowiada na pytanie „jak”? „kiedy”? „gdzie”? nie odpowiadając na pytanie „czym”?
Bardzo dobrym dopełnieniem idei Zarządzania Problemami będzie w tym przypadku znane również z koncepcji Lean Manufacturing tzw. TPM „Total Productive Maintenance (całkowite produktywne utrzymanie ruchu maszyn)”. W koncepcji Lean jest to metoda, której celem jest przeciwdziałanie zużywaniu się maszyn i urządzeń w produkcji oraz maksymalizacja ich efektywności.
Metody tej pozornie nie da się przełożyć na usługi w sektorze IT. W teorii istnieje bardzo daleka droga od przemysłu i środowiska produkcyjnego do strefy usługowej jeszcze ze szczegółowym uwzględnieniem usług IT.
Nie można jednak zapominać, że za każdą z usług stoi technologia, system a potem jeszcze konkretna infrastruktura. Czyli w tym momencie stosując podejście, rozbijając usługę na czynniki pierwsze (składowe) i spoglądając na nie odrębnie a nie całościowo, środowisko to zaczyna bardziej przypominać to znane z produkcji. Elementy infrastruktury podobnie jak w przemyśle muszą ze sobą współpracować, aby dostarczać produkty i półprodukty dążąc do asemblacji całości. Co prawda infrastruktury i komponentów IT nie trzeba oliwić w dosłownym tego słowa znaczeniu jednak, jeśli za „oliwienie” przyjąć okresową konserwację jak czyszczenie buforów, zwalnianie pamięci, aktualizacje sprzętu i oprogramowania to takie czynności i elementy zaczynają spełniać kryteria metody TPM używanej w środowisku produkcyjnym.
Rozpoczynając badania środowiska przemysłowe w TPM wyróżnia się sześć wielkich strat (rodzajów marnotrawstwa):
- awarie,
- straty wynikające z przygotowania urządzeń do pracy,
- nastawienia i przezbrojenia,
- pracę maszyn na zwolnionych obrotach,
- mikro przestoje i bezczynność maszyn,
- braki jakościowe, poprawki i odpad produkcyjny.
Natomiast wzorem wcześniejszych założeń i przyrównania obu sytuacji można wychwycić analogie działań pomimo ich różnic. Działania te będą adekwatne oraz będą połączone celem, którym jest proaktywne przeciwdziałania awariom czy przestojom już niezależnie czy będzie to przemysł czy usługi IT. Mapowanie sześciu wielkich strat według TPM odwzorowujące usług IT wygląda według autora następująco:
Przyrównanie zasad TPM Usługi vs Przemysł
|
Oryginalny TPM - marnotrawstwa |
„Usługowy” TPM- marnotrawstwa |
|
awarie |
awarie |
|
straty wynikające z przygotowania urządzeń do pracy |
straty wynikające z przygotowania urządzeń (komputery, laptopy, telefony, serwery, sieć, aplikacje) do pracy |
|
nastawienia i przezbrojenia |
rekonfiguracje systemowe |
|
pracę maszyn na zwolnionych obrotach |
niewystarczająca dostępność zasobów, wolna transmisja danych |
|
mikro przestoje i bezczynność maszyn |
niewłaściwa alokacja zasobów, brak odpowiednich mechanizmów HA (High Availability – wysokiej dostępności) |
|
braki jakościowe, poprawki i odpad produkcyjny |
błędy w programach, zapełniające się pamięci |
W myśl celów TPM dobrym podejściem do proaktywnego zarządzania problemami będzie właściwe zarządzanie zdarzeniami oraz skuteczne procesy konserwacji infrastruktury i systemów (co za tym idzie usług). Dobrze przygotowany system monitoringu, który będzie wykrywał nieprawidłowości zachodzące w środowisku i reagował na nie odpowiednio szybko i skutecznie. Jest to jednak tylko jedno z kilku konceptów które można zaczerpnąć z Leanowego narzędzia.
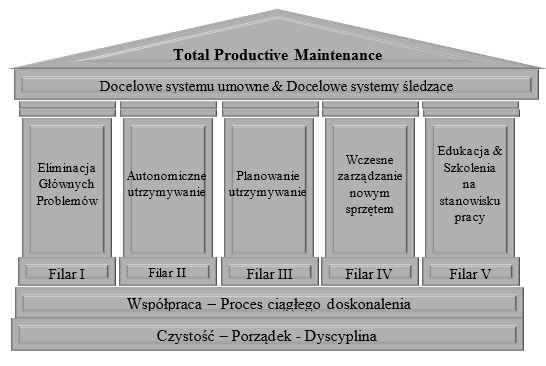
Identyfikując 5 filarów tworzących TPM, pomimo zastosowania dla procesów produkcyjnych można to przełożyć bezpośrednio do IT.
I Filar – Eliminacja głównych problemów – w myśl tej zasady najpierw powinny zostać naprawione problemy o największym znaczeniu (dla IT bądź organizacji), tak aby zyskać stabilność oraz zwolnić zasoby bądź kapitał ludzki potrzebny do ich obsługi.
II Filar - autonomiczna konserwacja – ten element narzędzia implikuje, że należy zautomatyzować pewne procesy konserwacyjne systemów np. cykliczne czyszczenie pamięci cache, okresowe porządki pamięciach dyskowych, automatyczne oczyszczanie systemów z nieużywanych zasobów (kont, pamięci)
III Filar – planowane konserwacje – wszędzie, gdzie nie jest możliwa automatyzacja procesów a są one krytyczne bądź wrażliwe należy manualnie przeprowadzać okresowe konserwacje np. wymiana sprzętu lub infrastruktury po ustalonym okresie czasu, aktualizacje programowania usługi, poprawki bezpieczeństwa
IV Filar – wczesne zarządzanie nowym sprzętem (oprogramowaniem) – nowość i świeżość rozwiązania nie powinna być powodem do lekceważenia jakichkolwiek objawów lub zgłoszeń mogących wskazywać na późniejsze problemy z usługą, należy od początku stosować założenia z wszystkich pozostałych filarów
V Filar – edukacja i szkolenie pracownika – w przypadku IT, będą to użytkownicy, ich wiedza dziedzinowa na temat danej usługi może przyczyniać się również na wyeliminowaniu problemów powodowanych przez brak znajomości zasad właściwego użytkowania rozwiązania oraz kreowania przez nich błędów prowadzących do awarii
W powyższym przypadku narzędzie TPM uzupełniające obszar zarządzania problemami wymusza na dziale IT konkretne już czynności zapewniające, że przeciwdziałanie im jest bardzo konkretne.
Sama idea praktyk ITIL co do problemów jest jak najbardziej słuszna, wprowadzenie podziału na proaktywne i reaktywne zarządzanie nimi również. Jeśli chodzi o konkrety to jednak ta metodyka jest bardzo lakoniczna i dostarcza za mało praktycznych informacji pozwalających na wydajne zarządzanie. Samo odwołanie do metod wykrywania błędów nie wystarczy. Elementarne narzędzia Lean takie jak TPM pozwalają w tym przypadku na bardziej szczegółową identyfikację obszarów, które będą kluczowe do przeciwdziałania występowania problemów oraz dosłowne przykazanie dla techników z obszaru eksploatacji usług na jakie obszary powinni zwracać uwagę mając na celu prewencję w zarządzanych przez nich usługach dostarczanych do biznesu.





